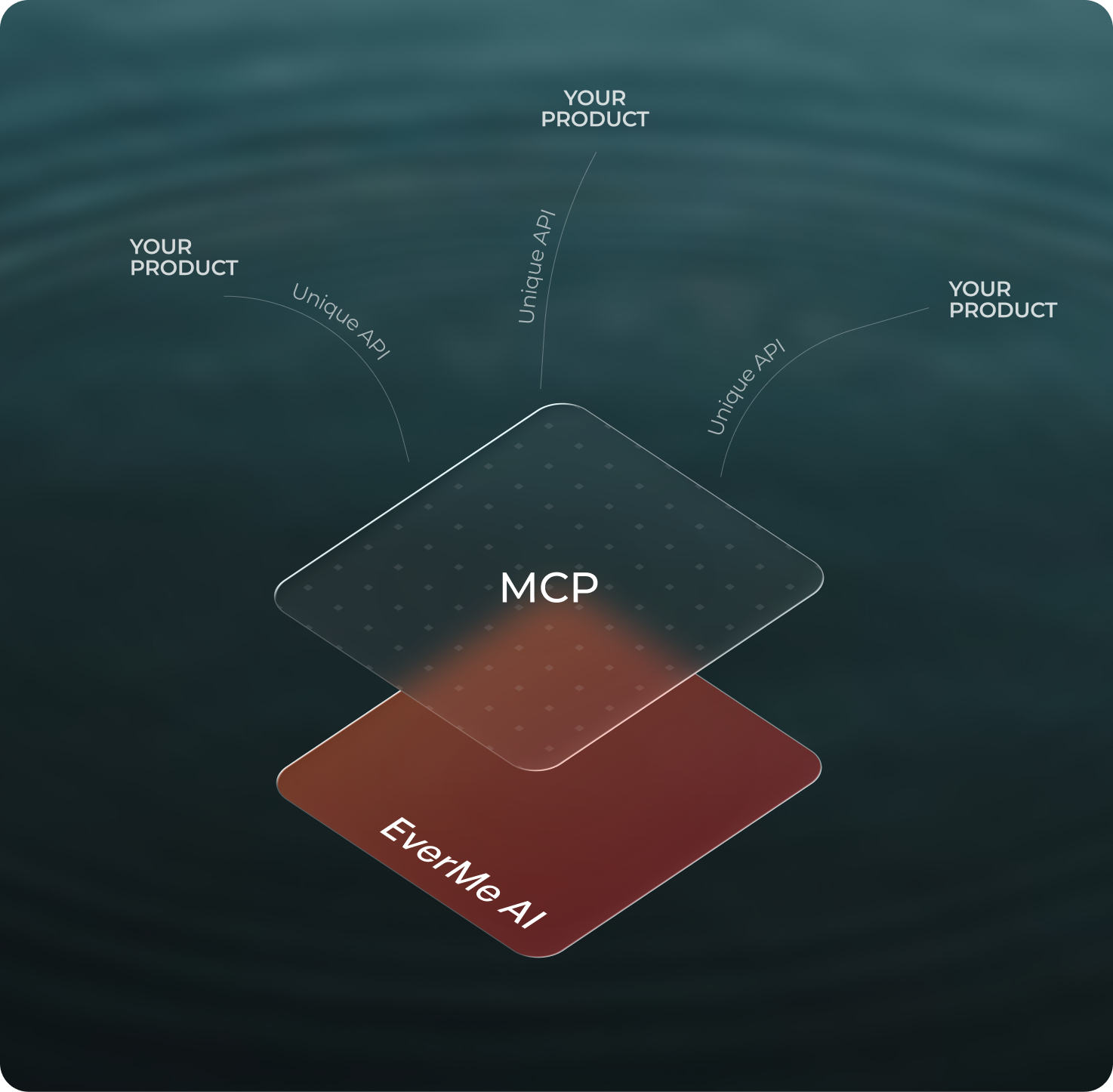
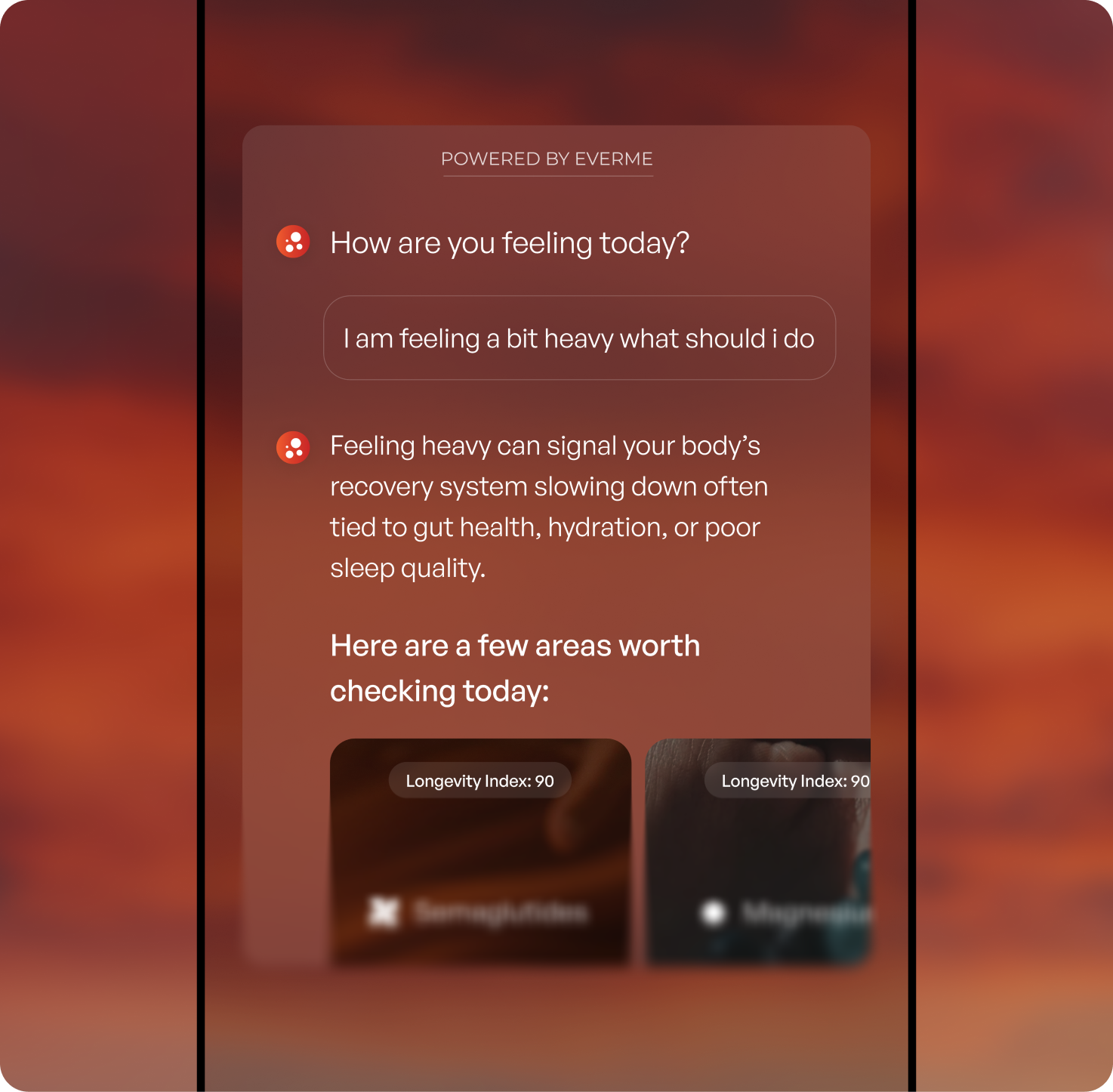
Our Scoring Methodology
130
Evaluation criteria per paper
Every piece of research is scored against 130 independent parameters, not keyword-matched, not summarised by an LLM.
17+
Specialist AI agents
A multi-agent architecture where each agent owns a distinct function: ingestion, scoring, validation, synthesis, retrieval.
18/100
Average research quality score
Across 67 scored papers on peptide therapies. High-volume wellness content doesn't survive the methodology, which is the point.
6.9 pt
Variance in competing systems
The same paper can score 36 on Monday, 43 on Friday in general-purpose models. EverMe scores are deterministic and auditable.